
Designing Minara’s Heterogeneous MoE Inference Engine

Bandwidth-First MoE Inference: CPU–GPU Pipelines Inspired by KTransformers
By Miracle Master, AI Safety & Trustworthy ML Researcher
Introduction
Modern Mixture-of-Experts (MoE) models are reaching hundred-billion and even trillion-parameter scales, so simply “putting everything on GPUs” is no longer enough, especially for systems that must make real-time financial decisions.
Minara is an AI financial assistant for digital finance: our agents read markets, coordinate across multiple tools, and generate execution-grade outputs. To keep this experience fast, stable, and affordable, we are moving toward a heterogeneous inference stack where CPUs and GPUs work together instead of competing for resources.
Why Inference Architecture Matters for Minara
Minara’s financial-agent workloads impose stricter requirements than a general-purpose chat model:
- fast responses to market conditions
- deterministic structured outputs
- cost-efficient scaling
- high concurrency across many agents
At the same time, modern Mixture-of-Experts (MoE) models are reaching hundred-billion and trillion-parameter scales. Even though only a small subset of experts is active per token, the full parameter pool must remain accessible, which is far exceeding the VRAM available on a single GPU.
This shifts the bottleneck from compute to memory bandwidth. Sparse experts must be fetched from DRAM for every token, and this dominates latency; PCIe simply cannot move these weights fast enough to sustain interactive speeds. As a result, the industry is moving toward heterogeneous inference, where CPUs and GPUs operate as coordinated compute units:
- GPUs handle high-frequency, latency-critical layers
- CPUs compute sparse experts directly from DRAM
- Overlapped scheduling hides CPU latency
Frameworks such as KTransformers show that heterogeneous inference is essential for running trillion-parameter MoE models on commodity hardware, and they inform parts of Minara’s own design. For Minara, moving from monolithic GPU inference to a coordinated multi-device pipeline is fundamental to delivering scalable, low-latency, execution-grade reasoning for our AI financial assistant that users rely on as their virtual CFO
Architectural Principles of Heterogeneous Inference
Modern MoE models activate only a small fraction of parameters per token, yet the full expert pool must remain accessible in memory, far beyond what any single GPU can hold. Heterogeneous inference addresses this by splitting the compute graph into two coordinated paths: a GPU-resident path and a CPU-computed path, as demonstrated in KTransformers.
GPU Resident Path (High-Frequency, High-Intensity Compute)
Components that run every token and have high arithmetic intensity remain on the GPU, including:
- Attention mechanisms
- Shared/always-active experts
- KV cache
These layers require both high throughput and low latency, making VRAM residency essential. Even with aggressive quantization, this path alone can saturate most consumer GPUs.
Minara Engineering Note:
For long-context financial reasoning and multi-agent workflows, keeping high-frequency paths permanently on GPU ensures predictable latency and stable coordination.
CPU Sparse Path (Expert Layers Computed In-Place)
MoE-routed experts often account for >90% of total parameters but are only sparsely activated (e.g., 8/256 per token). Instead of moving these large weights to the GPU, heterogeneous systems treat the CPU as an active compute device and execute sparse experts directly from DRAM.
Modern CPUs can run low-precision matmuls fast enough that these experts become practical to compute in-place, while local DRAM access avoids PCIe bandwidth limits. This allows expert computation to happen on demand without stalling GPU execution.
Minara Engineering Note:
Some internal reasoning paths behave similarly to sparse experts; computing them on CPU reduces VRAM pressure and improves cost scalability.
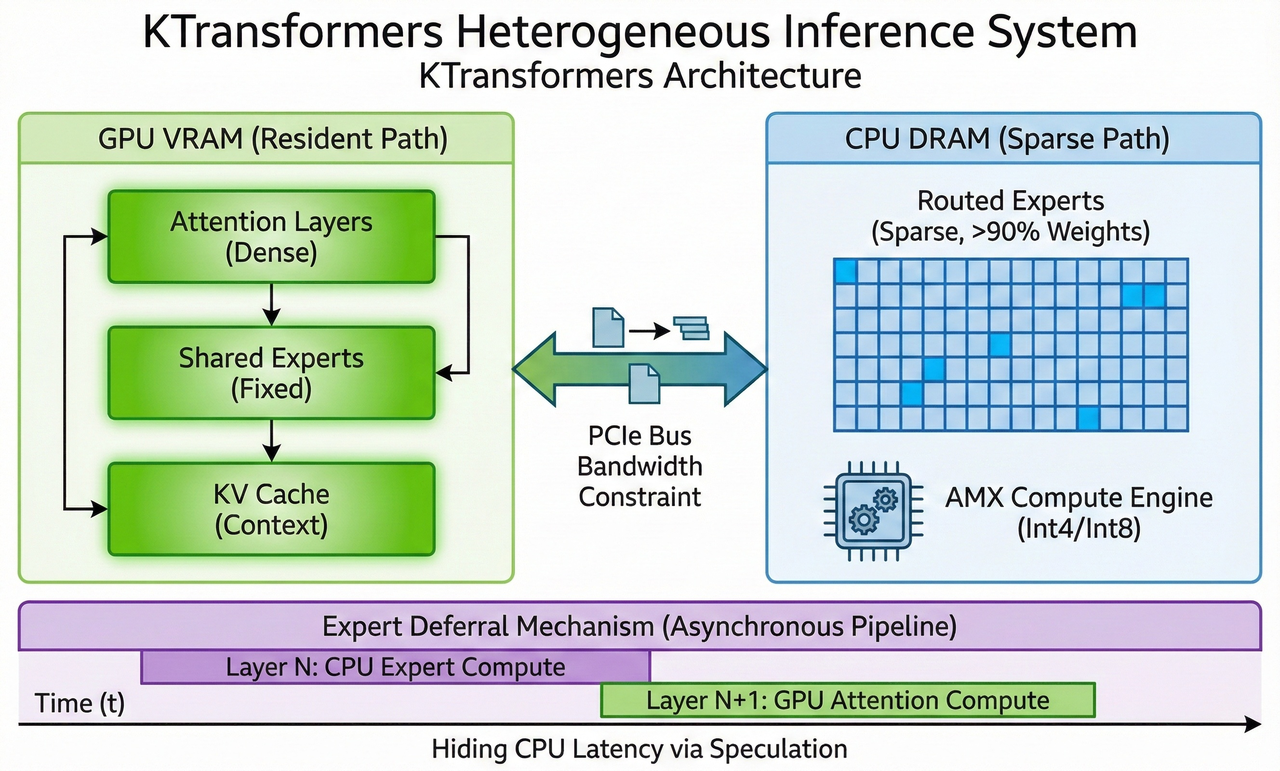
Expert Deferral — Hiding CPU Latency Behind GPU Execution
A key idea in systems like KTransformers is asynchronous deferral. Instead of blocking on CPU-computed experts at layer N, the scheduler continues GPU work for layer N+1 (e.g., attention) and merges the CPU results at the next synchronization point. In practice, this pipelines the computation and hides most CPU latency behind ongoing GPU operations.
Minara Engineering Note:
While powerful, deferral introduces temporal drift that can affect format-critical tasks (JSON, SQL, tool calls). Minara applies additional consistency checks to avoid downstream errors.
A Bandwidth-First Compute Model
For large MoE models, DRAM bandwidth (not raw FLOPs) quickly becomes the dominant bottleneck. Every token you generate requires streaming expert weights from memory, so the required bandwidth grows with:
- how many tokens per second you want to generate
- how many experts you activate per token
- what fraction of those experts live in CPU memory
- the bit-width of the weights (Int4 vs Int8, etc.)
Hardware Implications
These factors translate directly into which hardware setups are viable for interactive MoE inference:
- Moving from Int4 to Int8 roughly doubles bandwidth requirements.
- Typical dual-channel desktop systems cap out at only a few tokens per second for large MoEs.
- Eight-channel workstation platforms can reach well over 10 tokens per second, making them suitable for real-time use.
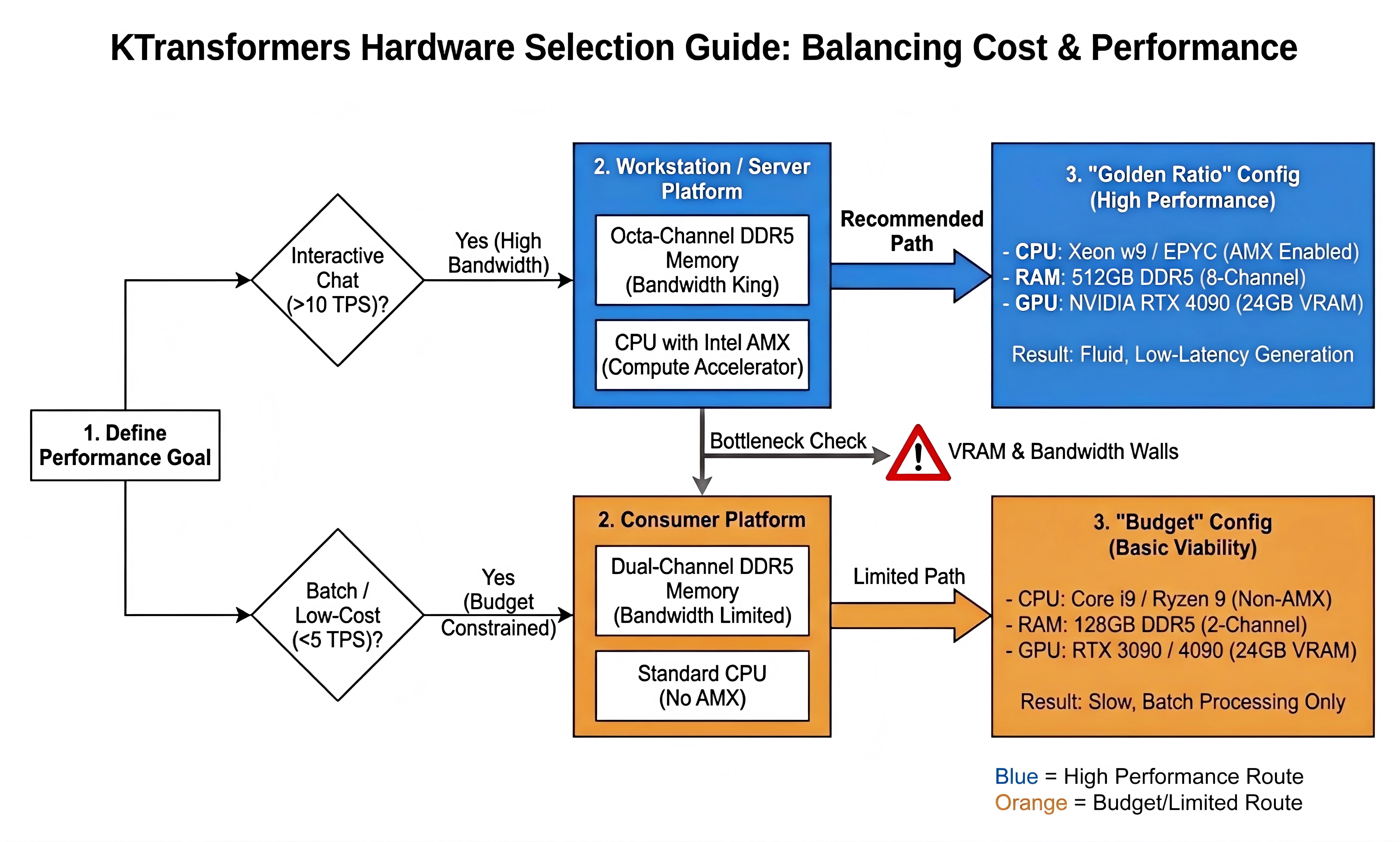
High-bandwidth, eight-channel workstation platforms are recommended for interactive MoE inference, while dual-channel consumer systems are only viable for low-throughput, batch-style workloads.*
Minara Engineering Note:
This bandwidth model informs Minara’s deployment strategy: how we place compute across CPU/GPU, which quantization schemes we adopt, and how we schedule workloads to balance latency, cost, and reliability for financial inference.
Why Heterogeneous Inference is the Pragmatic Choice for Minara
Minara coordinates multiple agents that perform long-horizon reasoning, interpret real-time market signals, and generate execution-ready outputs, transaction payloads, and multi-step workflow actions. These workloads impose constraints that make heterogeneous inference a natural fit.
Real-Time Financial Workloads Require Predictable Throughput
In digital finance, the real enemy is latency spikes caused by resource contention. Pure GPU inference for large MoE models often hits the "VRAM Wall," causing requests to queue up and creating unacceptable delays. Heterogeneous inference solves this by decoupling compute capacity from VRAM limitations. By offloading sparse experts to CPU memory, we prevent the GPU from becoming a hard bottleneck. This allows Minara to:
- Eliminate VRAM-induced request queuing
- Maintain stable token generation speeds even under high concurrent agent loads
- Scale context length without exponentially increasing hardware costs
Structural Integrity Through Architectural Isolation
Financial agents demand rigorous adherence to output formats (JSON, SQL). Standard quantization techniques required for heterogeneous inference can introduce noise.
However, the architectural flexibility of this stack is Minara’s advantage. We do not treat the model as a monolithic block. Instead, we physically isolate the "logic enforcement" layers (instruction following, output formatting) on the GPU in higher precision, while relegating the "broad knowledge retrieval" (sparse experts) to the CPU. This ensures that while the model’s reasoning scales cost-effectively, its execution syntax remains strictly guarded.
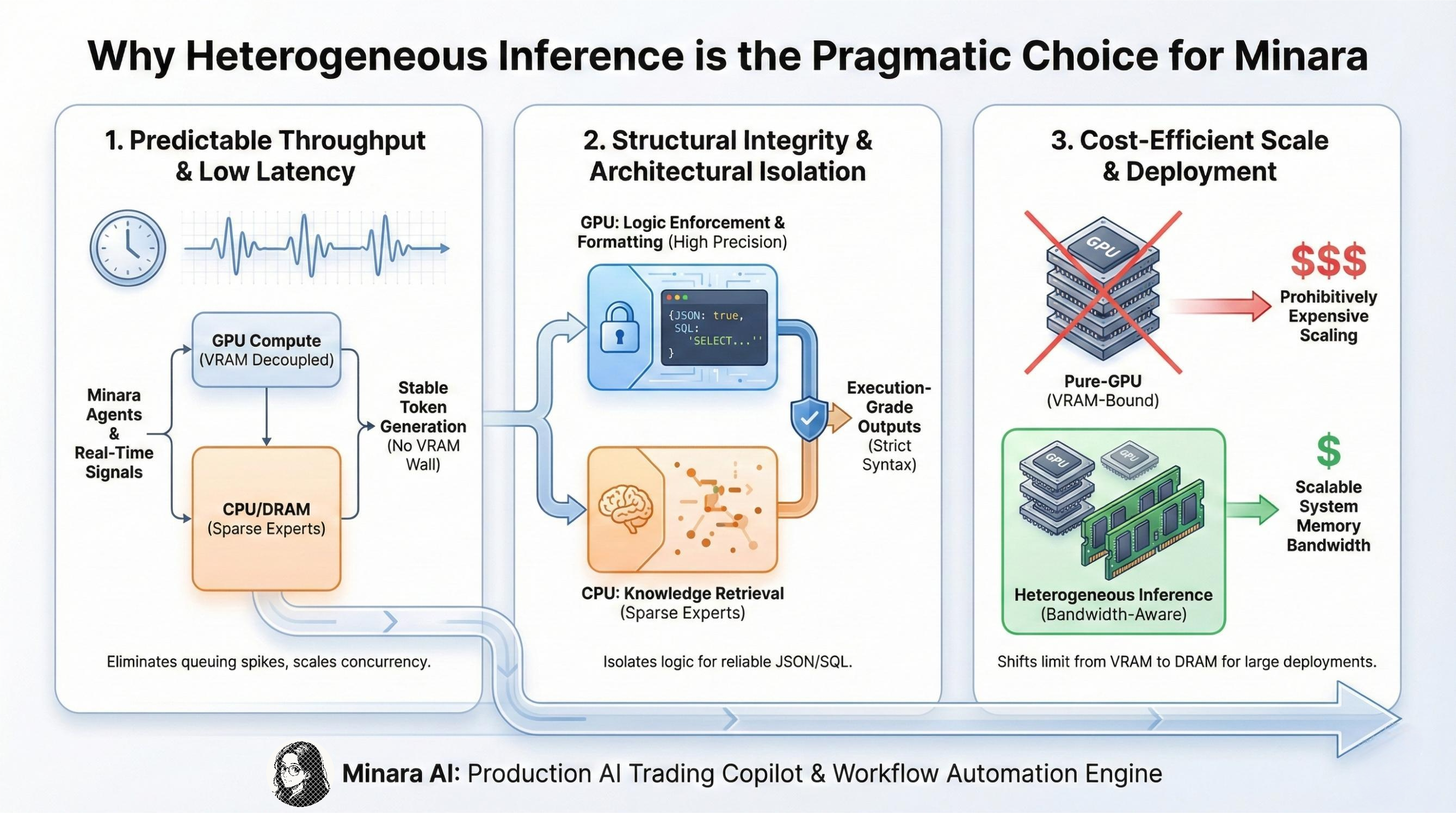
Large-Scale Self-Deployment Requires Cost-Efficient Compute
Finally, cost-efficient scaling is essential. A pure-GPU architecture forces all weights into VRAM, making large deployments prohibitively expensive. By running only high-frequency paths on GPU and offloading large, low-frequency components to CPU and DRAM, heterogeneous inference shifts the scaling limit away from VRAM and toward system memory bandwidth—resulting in predictable performance at far lower cost. This is crucial for supporting Minara’s multi-agent workflows, long-context scenarios, and automation pipelines with stable causal behavior.
These are not academic experiments: they sit behind Minara’s production AI trading copilot and workflow automation engine, which users depend on for real-time digital finance decisions.
How These Principles Inform Minara’s Inference Design
Minara operates at the intersection of AI reasoning and real-time digital finance, where an inference engine must satisfy three constraints simultaneously:
- latency — market-driven tasks must be resolved quickly
- precision — structured reasoning must remain deterministic
- scalability — multi-agent workflows require high concurrency
As workloads grow, single-device inference is no longer enough. Patterns proven in heterogeneous systems such as KTransformers provide a useful blueprint for how a Minara-style inference stack can be designed.
GPU as an “Executive Brain”
Conceptually, the GPU is the agent’s Executive Brain. A practical design is to keep latency-critical components (attention, KV cache, and routing / formatting logic) resident in VRAM.
Keeping expert selection on the GPU avoids PCIe bottlenecks on the critical path and helps preserve responsiveness under load.
CPU as an “Analyst Pool”
Sparse experts, which often account for the majority of parameters, can instead be treated as a CPU-side Analyst Pool. With low-precision matmuls on AVX-512 / AMX executed directly from DRAM, these experts provide large knowledge capacity on commodity hardware without requiring full H100-class clusters.
Separating Executive (GPU) from Analyst (CPU) roles is a natural way to deepen domain knowledge while keeping costs under control in a Minara-like financial agent system.
Context-Aware Scheduling (Design Direction)
Building on expert-deferral pipelines, one scheduling direction we explore is a context-aware mode switch:
- Exploration-oriented scheduling: During broad research or market analysis, CPU and GPU work can be overlapped aggressively to maximize throughput.
- Execution-oriented scheduling: When a tool call, transaction intent, or format-critical operation is detected, the system can switch to stricter synchronization to prioritize determinism and output safety.
This pattern captures the trade-off Minara cares about most: think as fast as possible when exploring, and behave as predictably as possible when acting.
Engineering Challenges — Ensuring Reliability in a Multi-Device System
Heterogeneous inference offers major performance benefits, but it also introduces reliability risks—especially in a product where outputs may drive financial actions. Minara focuses on three failure modes that matter most for execution-grade AI systems.
Quantization Noise in Long-Context Reasoning
Low-precision weights (Int4/Int8) are essential for bandwidth efficiency, but aggressive quantization can degrade numerical stability. In long-context tasks, this may weaken attention patterns, reduce instruction-following accuracy, or disrupt context retrieval.For Minara, even small deviations can surface as malformed JSON, broken SQL-like structures, or incomplete workflow actions.
Minara Engineering Note:
We apply precision-aware routing and context-stabilization techniques to keep high-value reasoning paths in higher fidelity.
Temporal Drift from Deferral Pipelines
Expert-deferral pipelines improve throughput by overlapping CPU expert computation with GPU execution, but relaxing strict layer ordering can introduce temporal drift—information from step k-1 influencing the output at step k.
While harmless in casual chat, such drift is risky for deterministic tasks like tool calls, structured outputs, or multi-step agent reasoning.
Minara Engineering Note:
We enforce strict synchronization boundaries around format-critical segments to prevent drift from affecting execution-grade outputs.
System Complexity and Multi-Device Reliability
Custom kernels, asynchronous schedulers, and mixed CPU/GPU execution increase performance but also introduce new classes of nondeterministic failures, such as:
- kernel-level behavior differences across hardware
- CPU microarchitecture variance in low-precision matmuls
- occasional desynchronization between CPU and GPU branches
Because Minara must run reliably across both cloud and controlled local environments, we rely on multi-stage validation, runtime monitoring, and output-verification layers to detect and contain such issues.
Minara Engineering Note:
Reliability is treated as a first-class design goal, not post-optimization. Structured outputs, tool safety, and agent state consistency depend on it.
In general chat settings, minor inconsistencies may be acceptable; for Minara, they are not. Real-time digital finance requires stability, determinism, and precise execution—which is why our adoption of heterogeneous inference prioritizes reliability as much as performance.
Building the Next Generation of Minara Inference
Heterogeneous inference marks a fundamental shift in how large models are executed. As MoE architectures become standard and parameter counts push toward the trillion scale, the industry is moving from GPU-only thinking to distributed, bandwidth-aware, multi-device execution.
For Minara, this shift is not theoretical. Our agents operate in a high-stakes environment where latency, determinism, and reliability directly influence financial decisions and on-chain actions. We cannot rely on inference as a black box; we must actively shape how GPU residency, CPU-accelerated sparse compute, and cross-device pipelines interact under real workloads. This complexity brings its own challenges—from quantization noise to temporal drift and multi-kernel behavior—and managing these trade-offs is a core part of our engineering roadmap. We are not building an inference framework for its own sake; we are building the infrastructure required for real-time, execution-grade financial intelligence.
As we continue to evolve our stack, our goal remains the same: deliver fast, stable, and trustworthy reasoning that users can rely on in the moments that matter.
Get started
If you’re curious how this infrastructure shows up as a user experience, you can try Minara now: AI financial assistant that turns natural-language intent into analysis, strategy, and execution across digital finance.
- App: https://minara.ai
- Homepage: https://minara.ai/home
- Docs: https://docs.minara.ai
- X: https://x.com/minara
- Blog: https://minara.ai/blog
- Community (Discord): https://discord.com/invite/minaraai
Read More

We Found 21 Money-Makers After Backtesting 236 TradingView Strategies
Over the past three months, our team built a pipeline that collects public PineScript strategies, rebuilds each one in our
Minara Workflow 2.0: From Workflow Generation to Workflow Copilot
Why Agentic Workflows Matter in Digital Finance Agentic workflows are becoming one of the most practical ways AI is applied

Minara Skill v2: The Missing Finance Stack in the Agentic Web
The Moment OpenClaw Changed Everything By now, you’ve probably seen OpenClaw or ClawdBot in the wild. OpenClaw shifts agents